前面介绍的所有的数据类型都是属于redis的底层数据结构,对象可以理解为是对底层数据结构的封装。
Redis 使用对象来表示数据库中的键和值,每次当我们在 Redis 的数据库中新创建一个键值对时, 我们至少会创建两个对象, 一个对象用作键值对的键(键对象), 另一个对象用作键值对的值(值对象)。
1 | typedef struct redisObject { |
表:对象的类型
| 类型常量 | 对象的名称 |
|---|---|
REDIS_STRING |
字符串对象(底层就是简单的字符串结构) |
REDIS_LIST |
列表对象 |
REDIS_HASH |
哈希对象 |
REDIS_SET |
集合对象 |
REDIS_ZSET |
有序集合对象 |
编码
与此同时,对象只是一种数据类型对外的表征展示,同一个类型对象的底层数据结构可以是不一样的,这个底层结构的就是用编码encoding 来记录的。
对象的编码
| 编码常量 | 编码所对应的底层数据结构 |
|---|---|
REDIS_ENCODING_INT |
long 类型的整数 |
REDIS_ENCODING_EMBSTR |
embstr 编码的简单动态字符串 |
REDIS_ENCODING_RAW |
简单动态字符串 |
REDIS_ENCODING_HT |
字典 |
REDIS_ENCODING_LINKEDLIST |
双端链表 |
REDIS_ENCODING_ZIPLIST |
压缩列表 |
REDIS_ENCODING_INTSET |
整数集合 |
REDIS_ENCODING_SKIPLIST |
跳跃表和字典 |
每种类型的对象都至少使用了两种不同的编码, 下面的表列出了每种类型的对象可以使用的编码。
不同类型和编码的对象
| 类型 | 编码 | 对象 |
|---|---|---|
REDIS_STRING |
REDIS_ENCODING_INT |
使用整数值实现的字符串对象。 |
REDIS_STRING |
REDIS_ENCODING_EMBSTR |
使用 embstr 编码的简单动态字符串实现的字符串对象。 |
REDIS_STRING |
REDIS_ENCODING_RAW |
使用简单动态字符串实现的字符串对象。 |
REDIS_LIST |
REDIS_ENCODING_ZIPLIST |
使用压缩列表实现的列表对象。 |
REDIS_LIST |
REDIS_ENCODING_LINKEDLIST |
使用双端链表实现的列表对象。 |
REDIS_HASH |
REDIS_ENCODING_ZIPLIST |
使用压缩列表实现的哈希对象。 |
REDIS_HASH |
REDIS_ENCODING_HT |
使用字典实现的哈希对象。 |
REDIS_SET |
REDIS_ENCODING_INTSET |
使用整数集合实现的集合对象。 |
REDIS_SET |
REDIS_ENCODING_HT |
使用字典实现的集合对象。 |
REDIS_ZSET |
REDIS_ENCODING_ZIPLIST |
使用压缩列表实现的有序集合对象。 |
REDIS_ZSET |
REDIS_ENCODING_SKIPLIST |
使用跳跃表和字典实现的有序集合对象。 |
Redis 可以根据不同的使用场景来为一个对象设置不同的编码, 从而优化对象在某一场景下的效率。
就比如上面介绍压缩列表时提到的,在数据量不大的背景下(查找效率影响不大),为了优化存储空间就会被处理成压缩列表。
字符串对象
虽然名字叫字符串对象,但是实际上是简单赋值对象,毕竟字符串对象的编码可以是int 、 raw 或者 embstr。
浮点数也就是 long double 在redis底层也是存的字符串(也就是后两个),读写的时候都分别转一下。
int
顺便来说一下对象结构的应用,如果执行了
1 | redis> SET KEY 10000 |
那么字符串对象会将整数值保存在字符串对象结构的 ptr属性里面(将 void* 转换成 long ), 并将字符串对象的编码设置为 int 。当然这里的long看起来不是redis自定义的数据结构而是单纯的long类型数据结构
raw
如果字符串对象保存的是一个字符串值, 并且这个字符串值的长度大于 39 字节, 那么字符串对象将使用一个简单动态字符串(SDS)来保存这个字符串值, 并将对象的编码设置为 raw 。
看一下这下这个对象长啥样
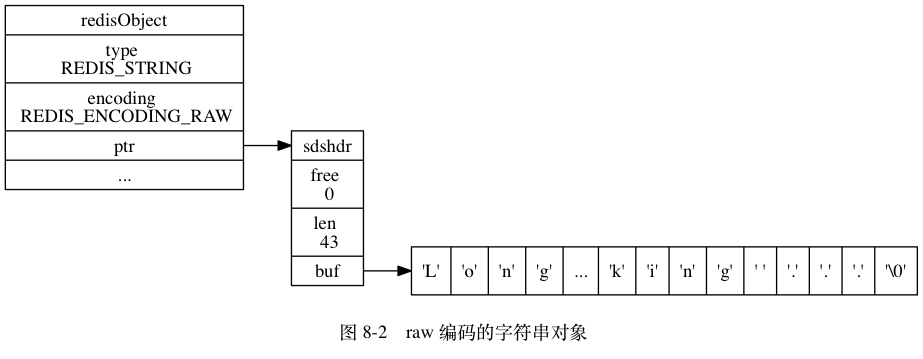
嘛感觉还是非常生动形象的。
embstr
如果字符串对象保存的是一个字符串值, 并且这个字符串值的长度小于等于 39 字节, 那么字符串对象将使用 embstr 编码的方式来保存这个字符串值。
本质上来说embstr也是和前面的压缩列表一样利用连续地址空间节约内存的东西(看得出对redis来说内存有多珍贵了)
embstr和raw的区别:
raw分配内存的时候,分别初始化redisObj和sdshdr,然后分配两块地址空间
而embstr分配内存时,一口气初始化redisObj和sdshdr,初始化成一块连续的地址空间。
嘛至于文档里说的调用和释放少掉用一次函数这种事情并不是重点啦
(这段是抄的但是讲的很有道理)至于为什么是39,这个讲起来就比较复杂了,我就慢点说。
embstr是一块连续的内存区域,由redisObject和sdshdr组成。其中redisObject占16个字节,当buf内的字符串长度是39时,sdshdr的大小为8+39+1=48,那一个字节是’\0’。加起来刚好64。是不是发现了什么?
编码转换
- int -> raw 当本来被设置为int的value变成字符串之后,就要进行编码转换
- embstr -> raw embstr是个只读的,所以只要对embstr进行了编辑,就会变成raw
同时 embstr 是只读的,也就是说其他数据类型不能转embstr,
字符串应该是使用率最高的东西了(我觉得)
列表对象
ziplist 和 linkedlist
一共有 ziplist 和 linkedlist两种
怎么看ziplist都是压缩列表的样子
linkedlist就是列表,在redis里是个双端列表的数据结构
不如在这里把文档里的例子都给一下,正好方便理解前面的东西(其实就是抄书)
Key: numbers value : 1 “three” 5
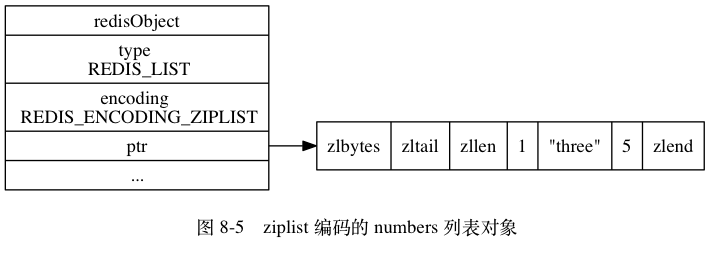
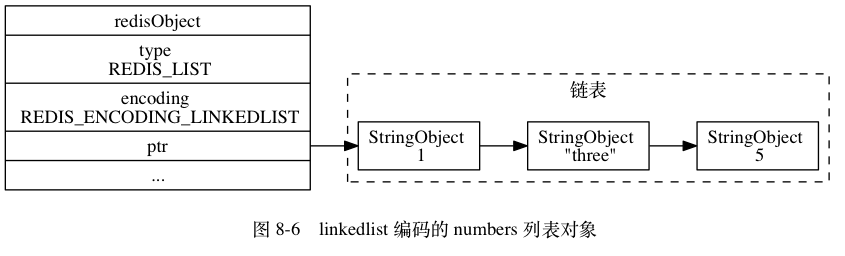
编码转换
当列表对象可以同时满足以下两个条件时, 列表对象使用 ziplist 编码:
- 列表对象保存的所有字符串元素的长度都小于
64字节; - 列表对象保存的元素数量小于
512个;
不能满足这两个条件的列表对象需要使用 linkedlist 编码。
这俩是可以在配置文件里配置的
哈希对象
ziplist 和 hashtable
先说hashtable吧,看起来就无比正常,底层是前面的字典结构,这里书上是这么写的:
- 字典的每个键都是一个字符串对象, 对象中保存了键值对的键;
- 字典的每个值都是一个字符串对象, 对象中保存了键值对的值。
根据前面看过的字典可以知道,dict->dictht->[]dictEntry,一个dictEntry里保存一个键值对,这个键是个指针,值可以是整数也可以是指针,书上的描述的意思应该就是每个键和值都指向了一个字符串对象的意思,嗯应该是的。
ziplist也就是压缩列表,数组的压缩列表很好理解嘛一个一个压起来,每个节点存个长度之类的东西就行。但是哈希有键值对的概念,所以就是先放key再放value的顺序压起来
- 保存了同一键值对的两个节点总是紧挨在一起, 保存键的节点在前, 保存值的节点在后;
- 先添加到哈希对象中的键值对会被放在压缩列表的表头方向, 而后来添加到哈希对象中的键值对会被放在压缩列表的表尾方向。
找肯定也是遍历找嘛这个不用怀疑,就不会和字典一样可以根据hash算法来加快找的速度
编码转换
用ziplist的条件和前面的数组一样,只要不满足条件就会从ziplist变成hashtable
集合对象
intset 和 hashtable
intset也就是前面的整数集合,这个比较好理解吧就是一堆整数集合。
hashtable就很神奇了,键值对里只有key是作为存储的,值则被置为null。不过仔细想想也很好理解,利用hashtable作为字段在不在set里的查找逻辑嘛,平时自己不也是这么写的
编码转换
当集合对象可以同时满足以下两个条件时, 对象使用 intset 编码:
- 集合对象保存的所有元素都是整数值;
- 集合对象保存的元素数量不超过
512个;
不能满足这两个条件的集合对象需要使用 hashtable 编码。
当然了那个512也是个配置
有序集合
ziplist 和 skiplist
跳表在前面看数据结构的时候就提过是用来处理有序集合的,可以利用跳表提高查找效率。
实际上一个skiplist包含一个跳表和一个字典
skiplist编码的有序集合对象使用zset结构作为底层实现, 一个zset结构同时包含一个字典和一个跳跃表:
1 | typedef struct zset { |
跳表本身没什么好说的,改存啥就存啥
字典就比较神奇了,key:每个节点的值,value:每个节点的score
值得一提的是, 虽然
zset结构同时使用跳跃表和字典来保存有序集合元素, 但这两种数据结构都会通过指针来共享相同元素的成员和分值, 所以同时使用跳跃表和字典来保存集合元素不会产生任何重复成员或者分值, 也不会因此而浪费额外的内存。
确实值得一提,不然肯定有人(比如我)会问在redis这种内存大过天的地方怎么会舍得分两份内存出来照顾有序集合的
但是为什么要用两个数据结构存有序集合?
ZRANGE 这种按顺序拿值的函数,那用跳表就ok了 O(nlogn)
ZSCORE 是需要根据值来获取score O(1)
嘛这样就可以理解了
压缩列表也没啥好说的,就是比较小的时候挨个排一排存起来,第一个是值第二个是score
编码转换
当有序集合对象可以同时满足以下两个条件时, 对象使用 ziplist 编码:
- 有序集合保存的元素数量小于
128个; - 有序集合保存的所有元素成员的长度都小于
64字节;
类型检查
背景,redis很多操作都是针对特定对象执行的,比如set对字符串对象,hset则是对哈希对象执行,类型检查就是为了确保特定的类型执行特定的指令。
类型特定命令所进行的类型检查是通过 redisObject 结构的 type 属性来实现的:
- 在执行一个类型特定命令之前, 服务器会先检查输入数据库键的值对象是否为执行命令所需的类型, 如果是的话, 服务器就对键执行指定的命令;
- 否则, 服务器将拒绝执行命令, 并向客户端返回一个类型错误。
多态
其实就是不同编码支持同一个函数的情况下,这个指令就被认为支持多态,比如linkedList和zipList
内存回收
redis利用引用计数来实现内存回收。
1 | typedef struct redisObject { |
对象的引用计数信息会随着对象的使用状态而不断变化:
- 在创建一个新对象时, 引用计数的值会被初始化为
1;- 当对象被一个新程序使用时, 它的引用计数值会被增一;
- 当对象不再被一个程序使用时, 它的引用计数值会被减一;
- 当对象的引用计数值变为
0时, 对象所占用的内存会被释放。
对象共享
可是为什么这个对象会被多个程序引用呢,这就涉及到了对象共享逻辑。
比如你创建一个值为10的字符串对象,key a和key b对应的值都是10的时候,他们会指向同一个字符串对象:10。
说白了也就是为了节约内存。
目前来说, Redis 会在初始化服务器时, 创建一万个字符串对象, 这些对象包含了从
0到9999的所有整数值, 当服务器需要用到值为0到9999的字符串对象时, 服务器就会使用这些共享对象, 而不是新创建对象。
当然这个数量也可以通过配置来修改
可以用 OBJECT REFCOUNT 来查看改对象引用量
比较有意思的是,目前Redis 只对包含整数值的字符串对象进行共享
简单来说原因就是时间复杂度->cpu耗时,整数匹配的时间复杂度为O(1) 而 字符串匹配的时间复杂度为 O(n)
而如果是一个哈希对象共享的话则会更加复杂,要判断键是否一致,再判断每个键下面的值是否一致,书上算出来的是O(n^2),但是我总觉得是O(kn)
而且字符串被重复利用比例和整数相比要低很多
空转时长
用到的是redisobject里面的lru 属性
1 | typedef struct redisObject { |
lru这个名字一出来就是老熟人了,lru记录了对象最后一次被命令程序访问的时间。用 OBJECT IDLETIME 命令可以打印出该对象的空转时长,也就是当前时间-lru
键的空转时长还有另外一项作用: 如果服务器打开了
maxmemory选项, 并且服务器用于回收内存的算法为volatile-lru或者allkeys-lru, 那么当服务器占用的内存数超过了maxmemory选项所设置的上限值时, 空转时长较高的那部分键会优先被服务器释放, 从而回收内存。