CAP
写在一切开始的cap,所有分布式系统都需要关注的内容
① C:Consistency,一致性,数据一致更新,所有数据变动都是同步的。
② A:Availability,可用性,系统具有好的响应性能。
③ P:Partition tolerance,分区容错性。以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择,也就是说无论任何消息丢失,系统都可用。
该理论已被证明:任何分布式系统只可同时满足两点,无法三者兼顾。 因此,将精力浪费在思考如何设计能满足三者的完美系统上是愚钝的,应该根据应用场景进行适当取舍。
Consistency
① 强一致性(strong consistency)。任何时刻,任何用户都能读取到最近一次成功更新的数据。
② 单调一致性(monotonic consistency)。任何时刻,任何用户一旦读到某个数据在某次更新后的值,那么就不会再读到比这个值更旧的值。也就是说,可获取的数据顺序必是单调递增的。
③ 会话一致性(session consistency)。任何用户在某次会话中,一旦读到某个数据在某次更新后的值,那么在本次会话中就不会再读到比这个值更旧的值。会话一致性是在单调一致性的基础上进一步放松约束,只保证单个用户单个会话内的单调性,在不同用户或同一用户不同会话间则没有保障。
④ 最终一致性(eventual consistency)。用户只能读到某次更新后的值,但系统保证数据将最终达到完全一致的状态,只是所需时间不能保障。
⑤ 弱一致性(weak consistency)。用户无法在确定时间内读到最新更新的值。
基本结构
zk其实算是一个分布式管理系统,管理分布式节点的配置维护,可用性协调等等等等。打个最熟悉的比方hdfs里面,如果master节点挂了往往要再选举出一个master来,那么这个master节点挂了是怎么感知的呢,正常理解肯定是定时ping,但是利用zk的话就可以注册节点并实时感知到master节点的状态,并且可以很方便地进行选举,从而减少了大量集群内部通信压力
实际上,hdfs,kafka,hBase等等底层的调度都用了zk
目录
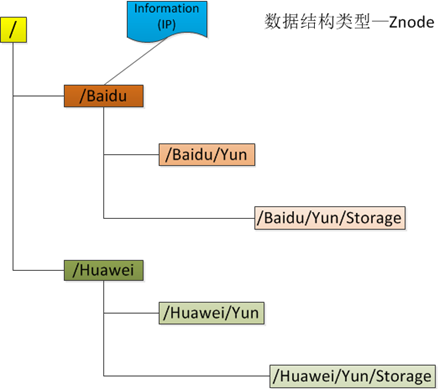
zk的目录结构和文件系统非常相似,有父节点,父节点下面可以创建子节点。
每个节点用路径来表示,路径必须是绝对且唯一的
znode
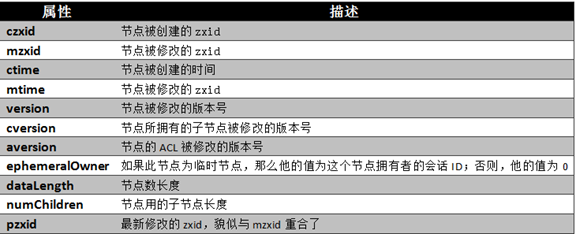
每个节点被称为一个znode,每个Znode由3部分组成:
① stat:此为状态信息, 描述该Znode的版本, 权限等信息
② data:与该Znode关联的数据
③ children:该Znode下的子节点
每个znode节点都有以下属性,后面会具体讲
znode有以下几个特征:
数据访问
- ZooKeeper中的每个节点存储的数据要被原子性的操作。也就是说读操作将获取与节点相关的所有数据,写操作也将替换掉节点的所有数据。另外,每一个节点都拥有自己的ACL(访问控制列表),这个列表规定了用户的权限,即限定了特定用户对目标节点可以执行的操作。
ZooKeeper中的节点有两种,分别为临时节点和永久节点。节点的类型在创建时即被确定,并且不能改变。
- 临时节点:该节点的生命周期依赖于创建它们的会话。一旦会话(Session)结束,临时节点将被自动删除,当然可以也可以手动删除。虽然每个临时的Znode都会绑定到一个客户端会话,但他们对所有的客户端还是可见的。另外,ZooKeeper的临时节点不允许拥有子节点。
- 永久节点:该节点的生命周期不依赖于会话,并且只有在客户端显示执行删除操作的时候,他们才能被删除。
当创建Znode的时候,用户可以请求在ZooKeeper的路径结尾添加一个递增的计数。这个计数对于此节点的父节点来说是唯一的,它的格式为”%10d”(10位数字,没有数值的数位用0补充,例如”0000000001”)。当计数值大于232-1时,计数器将溢出。
功能和原理
基本操作
每个znode的基本操作有九个
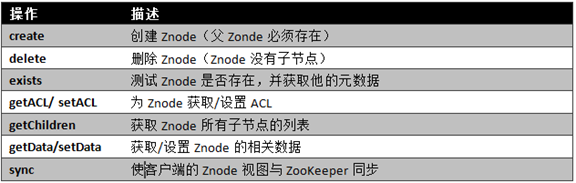
watcher
简单来说就是监听一个节点的变化,如果发生变化的话就会触发监听事件并且把消息传给监听的客户端,监听是一个一次性事件,结束之后需要重新设置watcher
watch类型
ZooKeeper所管理的watch可以分为两类:
① 数据watch(data watches):getData和exists负责设置数据watch
② 孩子watch(child watches):getChildren负责设置孩子watch
我们可以通过操作返回的数据来设置不同的watch:
① getData和exists:返回关于节点的数据信息
② getChildren:返回孩子列表
因此
① 一个成功的setData操作将触发Znode的数据watch
② 一个成功的create操作将触发Znode的数据watch以及孩子watch
③ 一个成功的delete操作将触发Znode的数据watch以及孩子watch

原理
1 | public class WatchManager { |
WatcherManager类用于管理watchers和相应的触发器。watchTable表示从节点路径到watcher集合的映射,而watch2Paths则表示从watcher到所有节点路径集合的映射
注册:客户端调用getData之后,服务器收到请求,就会将数据节点的路径以及 ServerCnxn(远程通信信息) 信息存储到 WatchManager 的 watchTable 和 watch2Paths 中。而同时客服端收到返回之后,也会在本地注册watcher到一个watchmanager
触发:客户端调用setData之后,服务器收到请求,修改完数据之后调用triggerWatch方法,服务器从之前的 watchManager 中获得 watchers,然后一个个调用 process 方法发送通知到客户端。客户端收到请求后转为watchedEvent进入waitingEvent队列,最终取出并执行processevent
权限管理(ACL)
创建每个znode都会产生一个acl列表,列表中每个ACL 包括:
权限perms
- Create 允许对子节点Create 操作
- Read 允许对本节点GetChildren 和GetData 操作
- Write 允许对本节点SetData 操作
- Delete 允许对子节点Delete 操作
- Admin 允许对本节点setAcl 操作
验证模式scheme
- Digest:Client 端由用户名和密码验证,譬如user:pwd
- Digest: Client 端由主机名验证,譬如localhost
- Ip:Client 端由IP 地址验证,譬如172.2.0.0/24
- World :固定用户为anyone,为所有Client 端开放权限
具体内容expression:Ids
Server 收到Client 发送的操作请求(除exists、getAcl 之外),需要进行ACL 验证:对该请求携带的Author 明文信息加密,并与目标节点的ACL 信息进行比较,如果匹配则具有相应的权限,否则请求被Server 拒绝。
会话
一旦客户端与一台ZooKeeper服务器建立连接,这台服务器就会为该客户端创建一个新的会话。正常来说会话是长期的,保证客户端与zk服务器的正常连接,直到客户端主动断开连接,但是有两个意外情况:
会话超时,每个会话仍旧有一个超时时间,如果服务器在超时时间段内没有收到任何请求,则相应的会话会过期。一旦一个会话已经过期,就无法重新打开,并且任何与该会话相关联的短暂znode都会丢失。
解决方法:只要一个会话空闲超过一定时间,都可以通过客户端发送ping请求(也称为心跳)保持会话不过期。ping请求由ZooKeeper的客户端库自动发送,所以我们使用的时候不用考虑会话过期问题,同时ping也可以用来检测连接的服务器是否有问题
服务器故障:上面说到的,ping的时候可以监测服务故障(所以ping的时间间隔不应该太长)
ZooKeeper客户端可以自动地进行故障切换,切换至另一台ZooKeeper服务器。并且关键的一点是,在另一台服务器接替故障服务器之后,所有的会话和相关的短暂Znode仍然是有效的。
但是另一台服务器接替故障服务器之后,之前的watcher和重连过程中znode发生的变化都会丢失,需要客户端重新设置watcher
集群
分布式系统的单点故障:主节点挂了
正常来说,如果master节点挂了,会重新选举一个新master节点,怎么判断主节点挂了呢?
– 传统方式是采用一个备用节点,这个备用节点定期给当前主节点发送ping包,主节点收到ping包以后向备用节点发送回复Ack ,当备用节点收到回复的时候就会认为当前主节点还活着,让他继续提供服务。
但是如果备用节点到主节点的网络有问题会怎么样?
– 备用节点会自动升级成主节点,那从节点就乱了,一部分汇报给了主节点,一部分汇报给了备用节点
最开始提到的,hdfs利用zk来感知节点故障并且进行选举,这个逻辑其实是把“故障转移到了ZooKeeper身上”
那么zk本身就需要保证自己不会出现上面描述的故障
先说一下zk是怎么做的:在master节点下注册比如两个节点,因为zk节点单调递增的属性,就可以用id最小的节点作为当前master节点,同时对其他节点都注册一个对比自己小一的节点的exist watcher。如果当前master节点挂了那么master节点会被删除,那么比master大一的节点会收到事件,并且自动启动master脚本称为master节点
但是如果zk自己只有一个机器,并且zk这个机器挂了呢?
– 那这个分布式系统会自动变成双master系统
所以zk需要首先有可用性和恢复性的保证
ZooKeeper运行模式
“独立模式“(standalone mode),即只有一个ZooKeeper服务器。这种模式较为简单,比较适合于测试环境,甚至可以在单元测试中采用,但是不能保证高可用性和恢复性。
“复制模式“(replicated mode),ZooKeeper运行于一个计算机集群上,这个计算机集群被称为一个”集合体“(ensemble)。
ZooKeeper集群
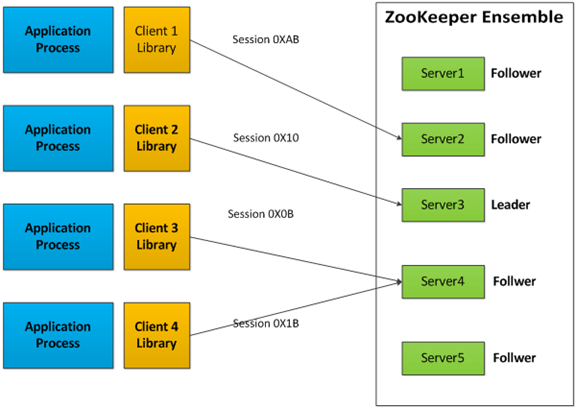
ZooKeeper通过复制来实现高可用性,只要集合体中半数以上的机器处于可用状态,它就能够提供服务。例如,在一个有5个节点的集合体中,每个Follower节点的数据都是Leader节点数据的副本,也就是说我们的每个节点的数据视图都是一样的,这样就可以有五个节点提供ZooKeeper服务。并且集合体中任意2台机器出现故障,都可以保证服务继续,因为剩下的3台机器超过了半数。
ZK集群中每个Server,都保存一份数据副本。Zookeeper使用简单的同步策略,通过以下两条基本保证来实现数据的一致性:
① 全局串行化所有的写操作
读请求,由每台Server数据库的本地副本来进行服务。
写请求,需要通过一致性协议来处理:所有写请求都要被转发到一个单独的Server,称作Leader。ZK集群中其他Server 称作Follower,负责接收Leader发来的提议消息,并且对消息转发达成一致。
② 保证同一客户端的指令被FIFO执行(以及消息通知的FIFO)
集群可用性
为什么是半数以上机器呢?
其实所谓的集群是否可用,隐含的意思就是集群是否能选举出一个leader
一般情况下zk的选举用的是 majority quorums的方案:只有当超过一半的follower达成一致的时候,才会选举出leader->所以建议zk的节点是奇数
那么我们再回头看一下前面说的单点故障下多个master的问题,我们也可以称为脑裂问题,就是因为通信等问题导致一部分节点失去leader的消息,重新选举一个leader之后,网络恢复出现两个leader的问题。那么在zk的场合下我们假设遇到了这个问题,机房A有三台机器,机房B有两台,当机房A和B断连之后:
首先leader和follower之间是有心跳检测的,所以follower会很快判断自己和leader断连了并且进入选举
- leader是机房A的,那么机房B选不出leader,就会变成不可用的follower,直到网络恢复
- leader是机房B的,那么断开之后机房A会选出一个新leader,可以看一下最后的epoch位介绍,每次选一个新leader epoch位都会加一,那么当网络恢复之后,机房A和B的leader在通信的时候会判断epoch是否一致,epoch小的那个会自动重置
所以保证了zk集群不会出现脑裂问题,但是在场景2当网络恢复之前也会出现两个leader,所以还需要增加其他方案来保证不会出现脑裂问题
zk与cap
① 顺序一致性
来自任意特定客户端的更新都会按其发送顺序被提交。也就是说,如果一个客户端将Znode z的值更新为a,在之后的操作中,它又将z的值更新为b,则没有客户端能够在看到z的值是b之后再看到值a(如果没有其他对z的更新)。
② 原子性
每个更新要么成功,要么失败。这意味着如果一个更新失败,则不会有客户端会看到这个更新的结果。
③ 单一系统映像
一 个客户端无论连接到哪一台服务器,它看到的都是同样的系统视图。这意味着,如果一个客户端在同一个会话中连接到一台新的服务器,它所看到的系统状态不会比 在之前服务器上所看到的更老。当一台服务器出现故障,导致它的一个客户端需要尝试连接集合体中其他的服务器时,所有滞后于故障服务器的服务器都不会接受该 连接请求,除非这些服务器赶上故障服务器。
④ 持久性
一个更新一旦成功,其结果就会持久存在并且不会被撤销。这表明更新不会受到服务器故障的影响。
zab协议
ZAB原名叫做Zookeeper Atomic Broadcast,是一种支持崩溃恢复的原子广播协议。
背景:所有的读都是在follower中处理的,但是写操作都会被转发到leader手上由leader统一处理
消息广播
所有的事务必须由一个全局唯一的服务器协调处理,这个服务器叫做Leader,其他的服务器称为Follower。Leader服务器将事务转换成Proposal(提议),并将该提议分发给所有的Follower。Leader等待Follower反馈,一旦超过半数正确反馈后,Ledaer将会再次向所有的Follower服务器发送Commit消息,要求将前一个Proposal提交。
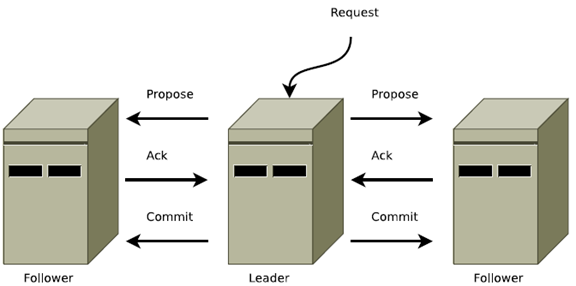
在广播过程中,Leader服务器会首先为这个事务分配一个全局单调递增的唯一ID,我们称之为事务ID(即ZXID)。Leader服务器会为每一个Follower服务器给自分配一个单独队列FIFO。将要广播的事务放到队列中,然后进行消息的发送。每一个Follower接受到事务后,会将其以事务日志的形式写道磁盘,成功后返回ACK消息,当Leader接收到半数以上的ACK后,就会广播一个Commit消息,通知Follower进行事务提交。
正常的数据更新就是用消息广播来处理的,但是如果leader结点崩溃的话,消息广播并不能解决问题
崩溃恢复
当Leader服务与过半的Follower失联,那么就会进入崩溃恢复模式。为了保证集群的正常运行,需要选举出新的Leader,这种叫做崩溃恢复,它不仅要让Leader知道自己是Leader节点,还要让其他的Follower知道他是Leader。
当崩溃恢复选取节点的时候会首先比较事务id(zxid),举个例子,当Leader发送Commit给其他节点的时候,假如有三个节点A、B、C,其中A收到了,当发送B的时候Ledaer突然崩了,那么新选举出来的节点应该是A,因为A的事务id最大。
恢复原则:
① 我们绝不能遗忘已经被deliver的消息,若一条消息在一台机器上被deliver,那么该消息必须将在每台机器上deliver。
方式:其实主要是借助leader选取的是最高zxid这个方案,当 Follower 连接上 Leader 之后,Leader 服务器会根据自己服务器上最后被提交的 ZXID 和 Follower 上的 ZXID 进行比对,比对结果要么回滚,要么和 Leader 同步。
② 我们必须丢弃已经被skip的消息。
方式:在我们的实现中,Zxid是由64位数字组成的,低32位用作简单计数器。高32位是一个epoch。每当新Leader接管它时,将获取日志中Zxid最大的epoch,新Leader Zxid的epoch位设置为epoch+1,counter位设置0。用epoch来标记领导关系的改变,并要求Quorum Servers 通过epoch来识别该leader,避免了多个Leader用同一个Zxid发布不同的提议。
paxos和zab对比:https://www.cnblogs.com/wuxl360/p/5817646.html
伸缩性
增加observer:简单来说,observer和follower一样作为读服务器,承载读请求,同时把写请求转发给leader
区别:在写请求的时候leader会发起proposal并收集投票,observer不参与接受propose和返回ack的过程,只接收最后的commit结果并同步本地数据
目的:
- 增加可伸缩性
我们现在可以加入很多 Observer 节点,而无须担心严重影响写吞吐量。虽然通知commit的阶段的开销还是会随着observer节点增长而增加,但是这里的开销相对来说非常低
- 增加广域网覆盖能力
可以把leader和follower这种需要大量通信交互的放在尽量近的网络内,保证往返时延不会太高,同时把observer放在需要访问 ZooKeeper 的任意数据中心中。这样,投票协议不会受到数据中心间链路的高时延的影响,性能得到提升。投票过程中 Observer 和领导节点间的消息远少于投票服务器和领导节点间的消息。这有助于在远程数据中心高写负载的情况下降低带宽需求。