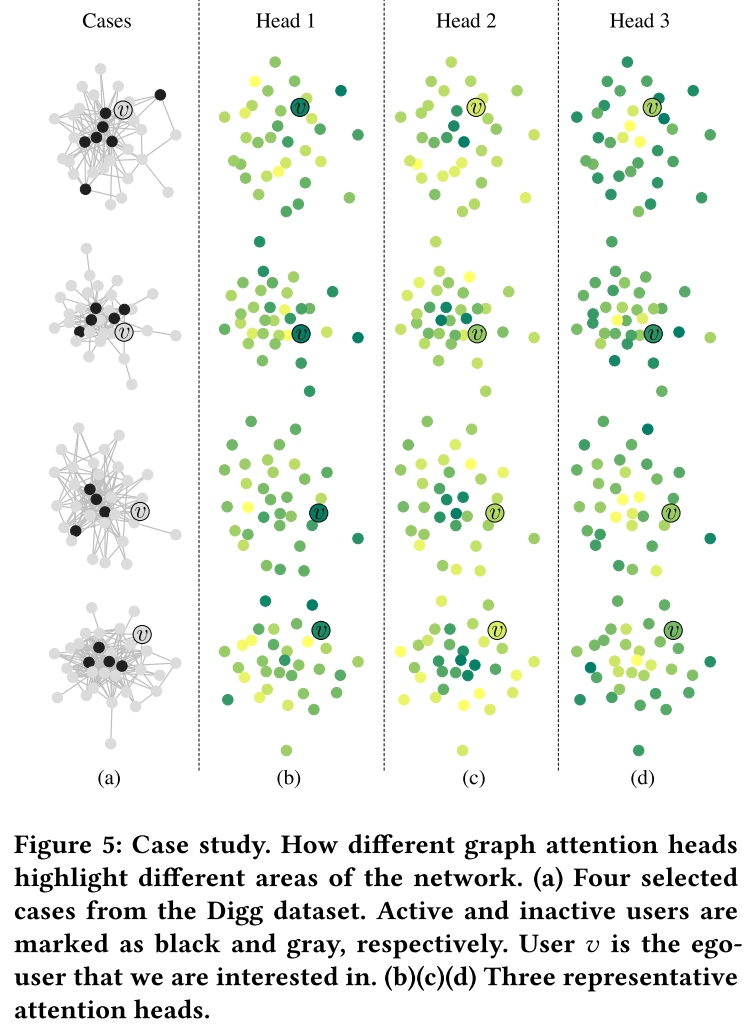
Rob Pike 的讲座
ppt:https://talks.golang.org/2012/concurrency.slide#2
vedio:https://www.youtube.com/watch?v=f6kdp27TYZs
就是一个非常基础但是很清楚的关于go concurrency的入门讲座。
讲在前面
concurrency and parallelism
不想详细说但是。。。从Rob的讲座来简单说就是
- concurrency:一个processor
- parallelism:多个处理器同时处理
(并发和并行的区别系列
CSP的开始
一切的开端:1978年hoare的论文,讲了communicating sequential process的原理。
Go and cocurrency
Go和其他实现csp语言最大的区别:其他语言比如Erlang是直接和process交互,而go语言是和channel进行交流。
Goroutine
- 简单来说:一个由go指令生成的单独运行函数
- 每个goroutine拥有自己的stack,同时这个stack的大小会随着执行的需要变大或缩小。这样的话和每个线程都要拥有自己独立的栈空间,并且为了保证运行的存储问题栈空间需要设计的足够大不一样,goroutine的初始化是很便宜的
- 从goroutine的调度上来看,一个线程可能执行着成百上千个协程(可以后面整理一下goroutine的调度问题)
- 当然从理解上来看可以把goroutine理解为一个非常非常轻便的线程
一个例子:
1 | func boring(msg string) { |
1 | package main |
运行结果:Program exited.
Channel
channel是一个goroutine的基础,具体介绍和goroutine简介里面基本上一模一样。
Select
A control structure unique to concurrency
看起来很像一个switch选项,但是是完全针对concurrency设置的,它和switch的区别:
- 每个选项都是一个communication(send or receive)
- 在开始时会衡量所有的communication
- 整个流程会一直卡住直到某个communication可以进行下去
- 如果同时有多个communication都可以进行,随机选取一个进行
- 如果所有communication都无法进行并且有一个default选项,不卡住直接走default
1 | select { |
Daisy-chain
菊花链并不是一个像select一样的函数,而是一个可以用go语言和协程来简单实现的功能
1 | func f(left, right chan int) { |
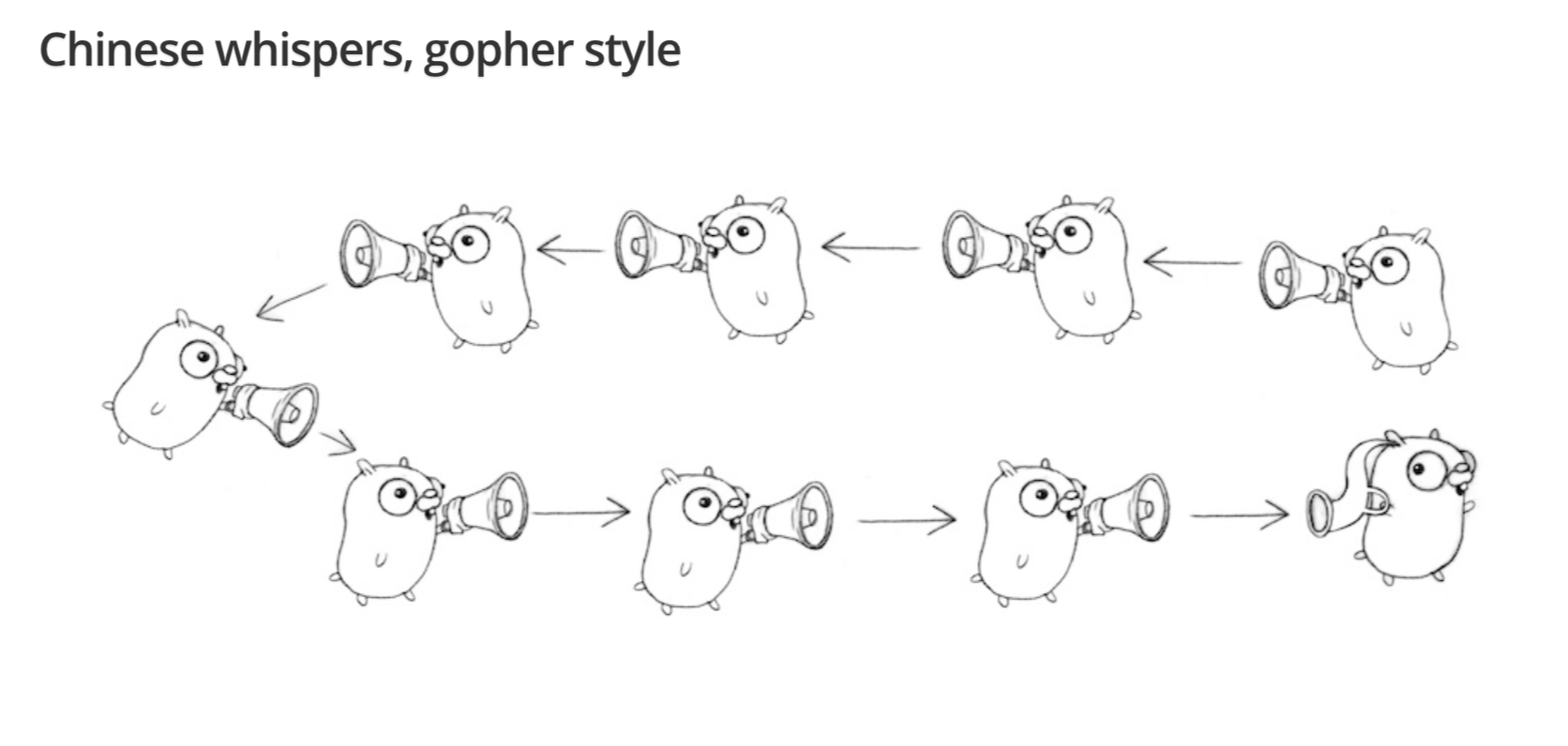
这段代码实现的就是上图所示的逻辑,看起来非常难以理解,实际上make一个channel之后返回的是指针,所以就是一开始left和right指向的都是最左端也就是终端的channel,之后新建了一个channel,并且让左边的channel去获取新建channel的值,然后再把left的指针指向它让它变成下一个左边。最后向最右边的channel输入一个值,触发了这条传话链。
从实际的运行情况来看,即使我们创建了上万个协程来实现这个功能,但是运行时间非常迅速,协程轻量的特征让他在创建和运行的时候非常迅速。
Attention
简单来说,go和concurrency是一种用于software construction的非常好的语言,但是很多时候不要杀鸡用牛刀,一个引用计数器就可以解决的问题就不要用channel了😂
go里面也提供了sync/atomic包来提供一些地址访问同步/锁等多线程会用到的操作,合理考虑使用channel。
Links
一些学习网站
Go Home Page:
Go Tour (learn Go in your browser)
Package documentation:
Articles galore:
Concurrency is not parallelism: