This is a realization of a simple program Prime by using java servlet.
反正就是个简单到不能更简单的实现,代码好像和书里的也没什么太大的差距。
唉这种弱智玩意儿还是打中文吧。。。
Thread in JAVA
JAVA 的 多线程编程主要流程还是放一张某博客抄来的图最简单粗暴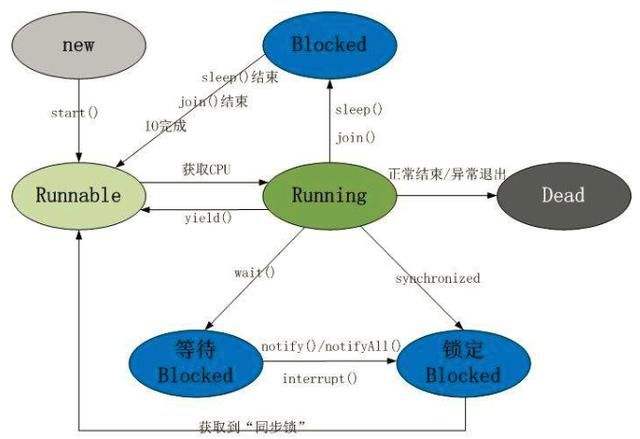
其实所有多线程编程思路都差不多,java多线程和C也没有本质上的区别(虽然C的操作系统当年就没怎么学好),这里就只简单memo一下在这份代码里用到的吧,毕竟真正的并发问题比自己随便搭个服务器玩玩要复杂太多了。
sychronized
可以适用于对象和代码上,本质就是锁住sychronized的对象,保证多线程的时候只有一个线程可以访问锁住的对象,防止了同时操作导致的各种问题。
sychronized用法主要有如下(随手写了两个有点诡异的例子):
锁住代码段:
1
2
3public synchronized void test(){
...
}与
1
2
3
4
5public void test(){
synchronized(this){
...
}
}等价。
锁住对象:
1
2
3
4
5
6
7
8ArrayList<int> A = new ArratList(15);
...
public void test(A){
...
synchronized(A){
...
}
}
注意:锁住的是同一个对象,如果在多线程操作里快乐地这么干了:
1 | class testClass{ |
然后在 main 里面是快乐地这么写的:
1 | for(int i=1; i<3; i++){ |
那么三个线程访问的是三个testClass类里面的test函数,完全不可能被锁住。
解决方法可以加全局锁(虽然我不是很能理解为什么不选择外部创造一个全局class,或者用Runnable共享一个class),但是写代码的情况千变万化有很多情况可能上述的方法不适用。
全局锁也有两种方法:
synchronized(.class):
1
2
3
4
5
6
7
8
9
10
11
12
13
14class testClass{
public void test(){
synchronized(testClass.class){
...
}
}
}
class myThread extends Thread {
public void run(){
testClass testC = new testClass();
testC.run();
}
}static synchronized
Runnable and Thread
又是基于个人的理解,Runnable 和 Thread 虽然从代码上来看都可以作为开启一个线程类的接口,但是从那张图来说Runnable可以理解为一个Thread准备就绪的状态,或者可以理解为,用同一个Runnable接口开启的不同线程,都是基于同一个Thread资源池来进行处理的。
Response Head
仿佛好像响应头才是书里介绍这段代码的重点,HTTP请求头和响应头的具体内容看一眼协议就行了,不想回忆我觉得我应该也没那么容易就忘了吧?吧。。。
在代码里用到的响应头是Refresh,让用户端每隔固定的时间就重新发送一次请求,也就是刷新浏览器。1
response.setIntHeader("Refresh", 1);
整个代码的github: Prime
用wireshark抓包的整个过程: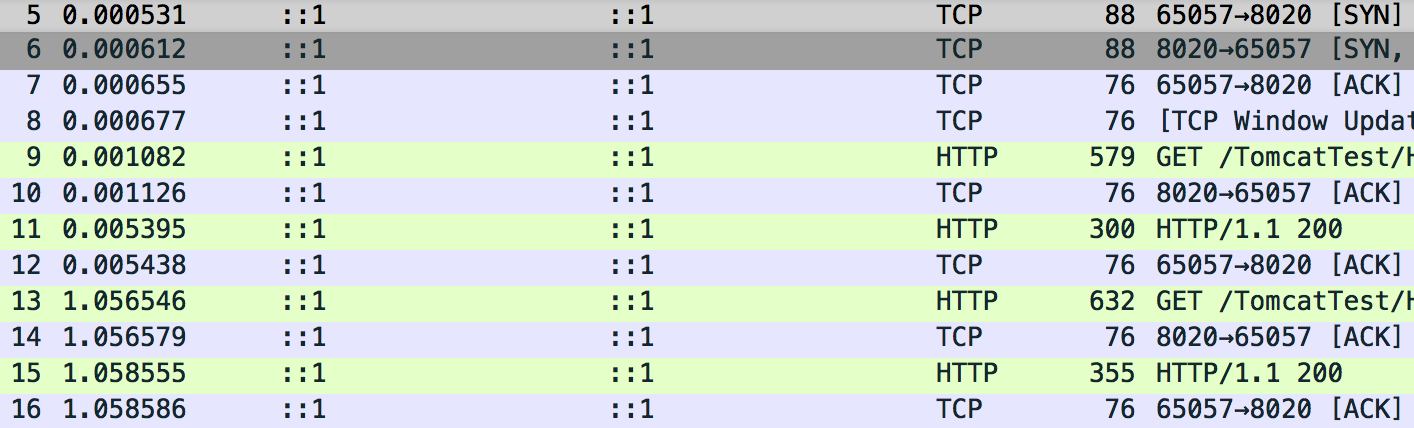
其中的什么三次握手http get就不看了,看一下第一次http response里面的内容吧
Hypertext Transfer Protocole
HTTP/1.1 200 \r\n
Request Version: HTTP/1.1
Status: 200
Refresh: 1\r\n
Content-Length:
Date:
…
在response包里面除了基础信息多了加粗标出来的Refresh。